Every AI system that enforces rules in production will eventually need those rules to change. A fraud threshold needs tightening. A credit eligibility condition needs updating after a regulatory revision. An agent authorization boundary needs expanding to cover a new tool. A pricing constraint needs adjusting for a new market segment.
The question is not whether your rules will change. The question is whether you have a process for changing them that does not introduce more risk than the change itself is intended to reduce.
Most teams do not. The prevailing method for changing rules in AI production systems in 2026 is still what it was in 2020 for application configuration: edit the rule (or the prompt, or the config file, or the database row), deploy the change, and watch for complaints. This approach works for the first ten rule changes. It becomes dangerous around the fiftieth. It becomes untenable around the hundredth, which is approximately when the first serious incident occurs and the team discovers they cannot answer basic questions about what changed, when, why, or what the previous behavior was.
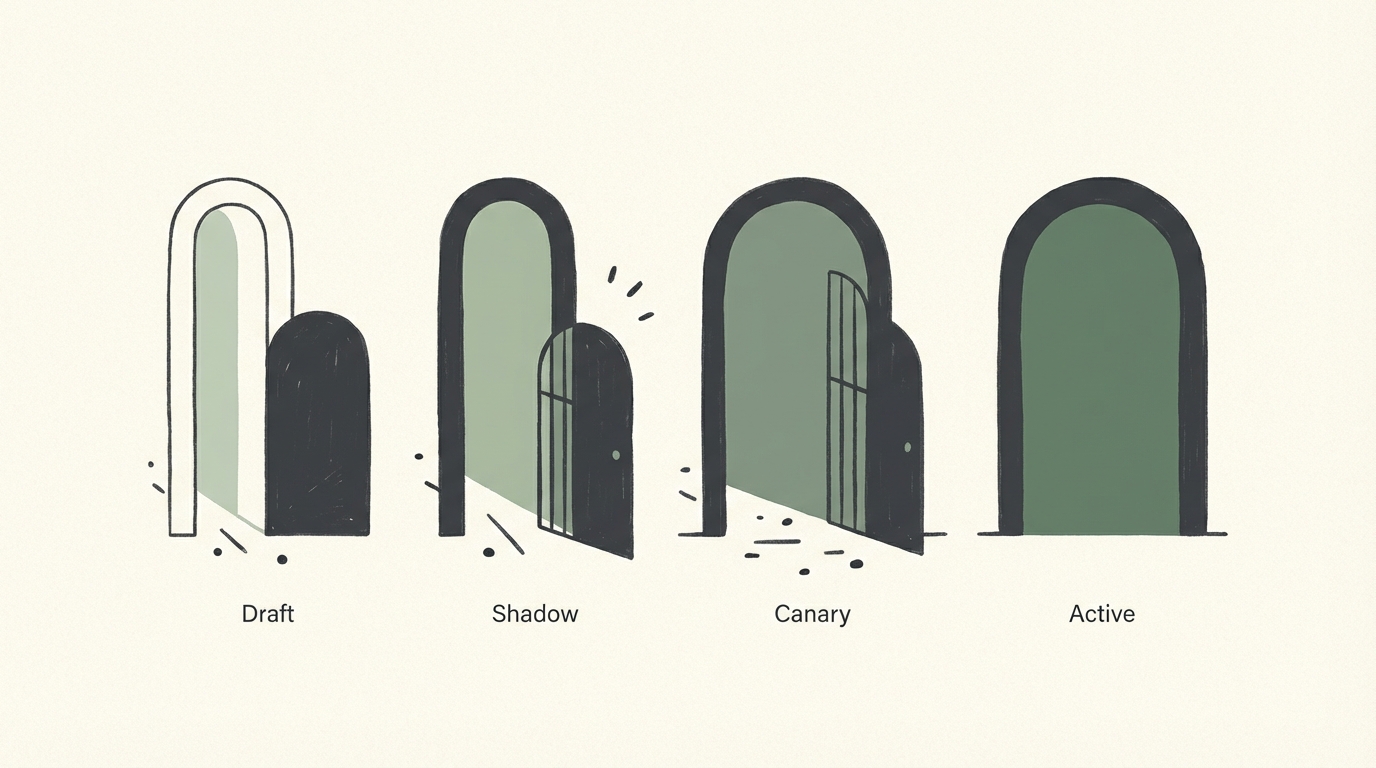
This article presents a four-stage governance model for rule changes in AI systems: draft, shadow, canary, active. Each stage serves a specific validation purpose. Together, they form a change process that is safe enough to run frequently, transparent enough to audit, and fast enough that teams do not route around it. The same pattern is implemented as a first-class capability in Memrail's Safe Rollout, which serves as the reference implementation discussed throughout this article.
Why "Edit and Redeploy" Fails at Scale
The edit-and-redeploy pattern has three failure modes that become progressively worse as the number of rules, the frequency of changes, and the blast radius of each rule increase.
Failure Mode 1: No Pre-Deployment Validation Against Live Traffic
When a rule change goes directly from an editor's screen to production enforcement, the first time the changed rule encounters real production traffic is the moment it begins affecting real outcomes. There is no intermediate step where the team can observe what the new rule would do before it does it. Unit tests against synthetic data catch syntax errors and obvious logical mistakes, but they cannot catch the interaction between a rule change and the actual distribution of production events — the edge cases, the unusual account states, the timing conditions that only manifest in live traffic.
The Google SRE Book establishes this principle in the context of software releases: the safest change is one that has been validated against production-like conditions before it reaches production enforcement. For software, staging environments approximate this. For rules, shadow evaluation is the equivalent — and most teams do not have it.
Failure Mode 2: No Incremental Exposure
Edit-and-redeploy is binary: the old rule applies to 100% of traffic, and then the new rule applies to 100% of traffic. There is no intermediate state where the new rule applies to 5% of traffic while the old rule handles the rest, allowing the team to measure outcomes on a small cohort before committing to full enforcement.
In software deployment, canary releases solved this problem decades ago. In rule management, the concept is identical but rarely implemented: route a configurable percentage of eligible events through the new rule while the majority continue under the old rule, measure the outcomes on both cohorts, and promote only when the canary cohort's outcomes meet defined criteria.
Failure Mode 3: No Instant Rollback
When a rule change produces unexpected behavior under edit-and-redeploy, reversing the change requires another edit-and-redeploy cycle. Someone needs to remember (or find) the previous rule definition, reconstruct it, deploy it, and verify the rollback. In the time between discovering the problem and completing the rollback, the incorrect rule continues to enforce against production traffic.
NIST SP 800-53's Configuration Management controls (specifically CM-3 and CM-4) establish the expectation that changes to information systems include documented rollback procedures with defined recovery time objectives. The edit-and-redeploy pattern, by its nature, cannot satisfy this expectation because rollback is a manual reconstruction rather than a system-supported operation.
The Four-Stage Model: Draft, Shadow, Canary, Active
The four-stage model decomposes a rule change into phases with distinct purposes. Each phase produces specific evidence that either supports promotion to the next phase or triggers a return to a previous phase for revision. The model is not theoretical — it reflects operational patterns described in Temporal's safe deployment practices and implemented in production rule management platforms.
| Stage | Purpose | Traffic Exposure | Evidence Produced |
|---|---|---|---|
| Draft | Authoring, peer review, test case definition | None — the rule evaluates no live traffic | Rule definition, test results, reviewer sign-off |
| Shadow | Validation against live traffic without enforcement | 100% of eligible events evaluated; 0% enforced | Shadow decision log, alignment metrics vs. current rule |
| Canary | Limited-scope enforcement with metrics comparison | Configurable slice (typically 5-10%) enforced | Canary outcome metrics, cohort comparison data |
| Active | Full promotion with instant rollback available | 100% of eligible events enforced | Production metrics, archived previous version for rollback |
The progression through these stages is not automatic. Each transition requires that defined criteria are met and, in governed environments, that a designated approver authorizes the promotion.
Stage 1: Draft — Authoring and Peer Review
A rule in Draft state is a first-class object in the rule management system. It has a name, an owner, a version identifier, a written definition, and a change rationale. It evaluates no live traffic and produces no decisions. Draft is the authoring environment.
The discipline at the Draft stage centers on three activities:
Precise definition. The rule must be specified with enough precision that another person — or an automated evaluation engine — can apply it to an event and produce the correct outcome without ambiguity. This is where most ad-hoc rule changes fail: the change is described in a Slack message or a JIRA ticket in natural language, and the translation to a precise rule definition happens implicitly in the head of whoever edits the configuration. Draft stage makes that translation explicit and reviewable.
Peer review. At minimum, someone other than the rule author reviews the definition before it advances. The review should address: does the rule express what the change rationale states? Are the conditions correctly bounded? Are there events that would match the conditions but should not trigger the rule? Are there events that should trigger the rule but would not match the conditions? This review is the rule-management equivalent of a code review, and it catches the same category of errors: logic mistakes that the author cannot see because they are too close to the intent.
Test case definition. For every rule change, define at minimum three test cases before the rule advances to Shadow: an event that should trigger the new rule, an event that should not trigger the new rule, and a boundary-condition event that sits at the edge of the trigger criteria. These test cases run automatically in subsequent stages to verify that the rule's behavior remains consistent as it moves through the pipeline.
# Example test case structure for a rule change
# Rule: Increase refund auto-approval threshold from $50 to $100
test_cases:
- name: "Below new threshold - should auto-approve"
event:
type: "refund_request"
amount: 75.00
account_age_days: 180
previous_refunds_30d: 0
expected_outcome: "auto_approve"
- name: "Above new threshold - should require review"
event:
type: "refund_request"
amount: 150.00
account_age_days: 180
previous_refunds_30d: 0
expected_outcome: "require_review"
- name: "At threshold boundary - should auto-approve"
event:
type: "refund_request"
amount: 100.00
account_age_days: 180
previous_refunds_30d: 0
expected_outcome: "auto_approve"The promotion criteria from Draft to Shadow: the rule definition is complete, all test cases pass, and the designated reviewer has approved. In regulated environments, this approval may require a compliance officer or a governance committee member, depending on the rule's scope and sensitivity.
Stage 2: Shadow — Validation Against Live Traffic Without Enforcement
When a rule advances to Shadow, it begins evaluating against live production events in real time. Every event that matches the rule's trigger criteria is presented to both the current active rule and the new shadow rule. Both rules produce decisions. Only the current rule's decision is enforced. The shadow rule's decision is logged for analysis.
Shadow evaluation answers the question that no amount of synthetic testing can answer: what would this rule change have done to my actual production traffic over the last N hours?
The primary metric during Shadow is decision alignment: the percentage of events on which the shadow rule and the current rule produce the same decision. For a rule change that is intended to be a narrow adjustment — tightening a threshold, adding an exception condition — you expect high alignment (95% or above) with divergence concentrated on the specific case the change targets. If the shadow rule diverges broadly from the current rule on events that the change was not intended to affect, something is wrong with the rule definition.
Shadow evaluation also reveals edge cases that test cases missed. Production traffic contains event patterns that synthetic test data does not: accounts in unusual states, events with missing or malformed fields, timing conditions that create unexpected interactions between rules. The shadow log captures every case where the shadow rule produced a decision, including cases where the rule encountered unexpected inputs. These cases are reviewed before promotion.
The duration of shadow evaluation depends on the rule's firing frequency and the team's confidence requirements. For a rule that evaluates thousands of events per day, 24-48 hours of shadow data may be sufficient. For a rule that fires on weekly events (such as a billing-cycle rule), shadow evaluation may need to run for one or two complete cycles to produce meaningful data.
The promotion criteria from Shadow to Canary: decision alignment meets the defined threshold, all divergences have been investigated and accepted or corrected, all automated test cases continue to pass, and the shadow log has been reviewed by the designated approver. If any divergence requires a rule correction, the rule returns to Draft, the correction is made, and shadow evaluation restarts.
Stage 3: Canary — Limited-Scope Enforcement With Metrics Comparison
In Canary stage, the new rule begins enforcing decisions — but only for a configurable percentage of eligible events. The typical starting slice is 5-10%, selected randomly from the eligible event population. The current rule continues to enforce for the remaining events. Both cohorts' outcomes are measured and compared.
Canary enforcement is the first stage where the rule change produces real outcomes for real users or systems. The shadow stage proved that the rule evaluates correctly. The canary stage proves that the rule's enforcement produces acceptable outcomes in production.
The distinction matters because evaluation and enforcement are not always equivalent. A rule may evaluate correctly (produce the right decision) but interact with downstream systems in unexpected ways during enforcement. For example, a rule that auto-approves a higher refund threshold may evaluate correctly, but the refund processing system may have its own limits that the rule does not account for, producing errors on enforcement that were invisible during shadow evaluation.
During Canary, the team monitors three categories of signal:
Direct outcome metrics. The metric the rule change is intended to affect. If the change is designed to increase auto-approval rates, measure auto-approval rates in the canary cohort versus the control cohort. If the change is designed to reduce false positives in fraud detection, measure false positive rates in both cohorts. The canary cohort should show the intended improvement without unexpected degradation.
Downstream effects. Metrics that the rule change is not intended to affect but could affect indirectly. Support ticket creation rates, payment failure rates, escalation volumes, processing latency. A rule change that improves its target metric but increases support ticket volume by 15% has a net-negative outcome that would not be visible from the direct metric alone.
Automated regression signals. The test cases defined in Draft stage run against every canary evaluation. Any test case failure during canary enforcement triggers an automatic alert and, if configured, an automatic rollback to the current rule. This is the fastest rollback signal available — faster than monitoring dashboards, faster than human review.
The First Round Review's analysis of engineering change management emphasizes that promotion criteria should be defined before the canary starts, not discovered during it. A common anti-pattern is to observe canary results and then retroactively define success criteria that match the observed outcomes. This is rationalization, not validation.
The promotion criteria from Canary to Active: the defined observation window has elapsed (commonly 48-72 hours for high-frequency rules), direct outcome metrics meet or exceed the target within the canary cohort, downstream metrics show no significant degradation, all automated test cases pass, and the designated approver authorizes full promotion.
Stage 4: Active — Full Promotion With Instant Rollback
When the canary succeeds, the rule promotes to Active: it applies to 100% of eligible events. The promotion is atomic — the transition from canary-percentage enforcement to full enforcement happens as a single versioned state change. There is no gradual ramp from 10% to 25% to 50% to 100%; the rule either meets the canary criteria and promotes, or it does not.
The previous rule version is not deleted. It is archived as an immutable record with its complete history: the dates it was active, the events it evaluated, the decisions it produced, and the promotion that superseded it. This archive serves two purposes: it is the rollback target if the promoted rule produces unexpected behavior at full traffic, and it is the audit record that documents the rule's complete lifecycle.
Instant rollback is a design requirement, not an operational aspiration. Rolling back a rule change should be a single operation that restores the previous version to Active status and demotes the current version. The operation should complete in seconds, not minutes. If your rollback procedure requires a code deployment, a configuration file edit, or a manual database update, your rollback is too slow for rules that evaluate at production scale.
Automated rollback triggers provide an additional safety net at the Active stage. Define metric thresholds that, if breached within the first N hours of full promotion, trigger an automatic rollback without human intervention. These thresholds should be conservative — they are a safety net for scenarios where a rule that passed canary criteria produces different outcomes at full traffic volume due to load-dependent effects, cohort distribution differences, or interaction effects with other recently promoted rules.
Worked Example: Tightening a Fraud Detection Threshold
The scenario: your AI system flags transactions for fraud review based on a risk score threshold. Transactions scoring above 0.7 are flagged for human review; transactions scoring below 0.7 are auto-approved. Your fraud team has evidence that the current threshold produces too many false negatives — legitimate fraud is getting through at scores between 0.6 and 0.7. They want to lower the threshold to 0.6, which will flag more transactions but also increase the review queue volume.
Draft. The rule change is defined: lower the flag-for-review threshold from 0.7 to 0.6. Test cases are written: a transaction at 0.65 (should now be flagged), a transaction at 0.55 (should still be auto-approved), a transaction at 0.60 exactly (boundary case — should be flagged). The fraud team lead and a compliance officer review the change and its rationale. The anticipated impact is documented: estimated 18% increase in review queue volume based on the score distribution of recent traffic.
Shadow. The rule enters shadow evaluation for 72 hours. The shadow log shows that the new threshold would have flagged 2,847 additional transactions that the current rule auto-approved. Of those, the fraud team samples 200 and confirms that 34 (17%) are transactions that the fraud model correctly identified as elevated risk but the current threshold allowed through. The team also identifies an unexpected pattern: 12 transactions from a single merchant account scored between 0.60 and 0.65 and were all legitimate volume from a high-transaction retailer. The team decides this is acceptable — the merchant's transactions will be reviewed quickly given their known pattern — and documents the finding.
Canary. The rule promotes to canary at 5% of transaction volume. Over 48 hours, the canary cohort shows the expected increase in flagged transactions. The review team processes both cohorts simultaneously. The canary cohort's flagged transactions include seven confirmed fraud cases that the current rule would have auto-approved. No false positive increase is observed in the canary cohort beyond the expected baseline. Review queue processing time increases by 12 minutes per reviewer per shift — within the team's operational capacity.
Active. The rule promotes to Active. The previous 0.7 threshold rule is archived with its complete history. Automated rollback is configured: if the review queue exceeds 150% of projected volume within the first 24 hours (indicating the score distribution has shifted or the canary sample was not representative), the system automatically reverts to the 0.7 threshold and alerts the fraud team.
Organizational Requirements: Who Owns What
A rule change process without clear ownership defaults to no process at all. The four-stage model requires three distinct roles, each with defined responsibilities.
Rule author. The person or team that identifies the need for the change, writes the new rule definition, defines the test cases, and documents the change rationale. For business rules, this is typically a domain expert — a fraud analyst, a compliance officer, a product manager. For technical rules (agent authorization boundaries, system constraints), this is typically an engineer.
Rule reviewer. A person other than the author who reviews the rule definition, test cases, and change rationale before the rule advances from Draft. The reviewer's responsibility is to identify ambiguities, missing conditions, and edge cases that the author may have overlooked. In regulated environments, the reviewer may be a compliance officer or a member of a governance committee.
Promotion approver. The person authorized to advance a rule from one stage to the next. In low-risk environments, the author and reviewer may be sufficient. In high-risk or regulated environments, promotion from Canary to Active may require approval from a governance committee, a risk officer, or a department head. The approval is recorded as part of the rule's audit trail.
These roles do not need to be dedicated positions. In a small team, one engineer may author rules while another reviews them, and a team lead approves promotions. In a large organization, a model risk committee may own promotion approval for rules governing financial decisions. The structure scales; the principle does not change: no rule change should be authored, reviewed, and promoted by the same person.
What the Change Record Should Contain
Every rule change that completes the four-stage process should produce a change record that answers the following questions without requiring additional investigation:
| Question | Answered By | Stage Produced |
|---|---|---|
| What changed? | Rule definition diff (previous version vs. new version) | Draft |
| Why did it change? | Change rationale document | Draft |
| Who authored and reviewed the change? | Author ID, reviewer ID, approval timestamps | Draft |
| What would the change have done to live traffic? | Shadow decision log and alignment metrics | Shadow |
| What did the change actually do at limited scale? | Canary cohort outcome metrics | Canary |
| Who authorized full promotion? | Promotion approver ID, approval timestamp | Canary to Active |
| What is the rollback target? | Archived previous rule version ID | Active |
This change record is not optional documentation — it is the evidentiary basis for demonstrating that rule changes are governed. In regulated environments, this record is what satisfies NIST SP 800-53 CM-3 (Configuration Change Control) requirements. In audit contexts, it is what turns a rule change from an unverifiable operational event into a documented, traceable governance action.
Common Anti-Patterns and How the Four-Stage Model Prevents Them
"We'll watch the dashboards." Relying on general-purpose monitoring dashboards to catch rule change problems is the most common anti-pattern. Dashboards show aggregate metrics. A rule change that affects 3% of events in a way that degrades a customer-facing outcome will not produce a visible inflection on an aggregate dashboard until the damage is already significant. Shadow evaluation catches these effects before any customer is affected. Canary metrics isolate the change's impact on a defined cohort where signal-to-noise ratio is high enough to detect small effects.
"It's just a small change." The perceived size of a rule change has no reliable correlation with its blast radius. A one-character change to a threshold value can affect every event that evaluates against that threshold. The four-stage model treats every rule change the same way — not because small changes are inherently dangerous, but because the cost of running them through the process is low and the cost of skipping the process when the "small change" turns out to have a large effect is high.
"We need this change in production now." Urgency is the most common reason teams bypass change governance. The four-stage model accommodates urgency by making each stage as fast as possible — not by providing a bypass. For a high-frequency rule, shadow evaluation can produce meaningful data in hours. Canary can produce meaningful data in a day. The total pipeline from Draft to Active for an urgent change in a well-instrumented system is 48-72 hours. If the change is so urgent that 48 hours is unacceptable, the team should be asking why they are in a position where a rule change is a production emergency — the answer usually points to a more fundamental governance gap.
"The old rule was never documented." This is not an objection to the four-stage model; it is the strongest argument for it. If the current rule was never documented, then the team does not have a precise definition of what the current behavior is, which means they cannot precisely define what the change will alter. The first step in implementing governed rule changes is often a rule documentation sprint: defining and recording the current rules before attempting to change them. This is uncomfortable work, but it is the prerequisite for any governed change process.
Integrating With Existing Change Management
Teams that already operate change management processes for software deployments — change advisory boards, deployment calendars, release trains — can integrate the four-stage rule change process without creating a parallel governance structure.
The integration points are straightforward. The Draft stage maps to your existing change request process: a rule change is a change request with a defined scope, rationale, and approval requirement. The Shadow stage maps to your existing staging or pre-production validation: the shadow log is the equivalent of integration test results for a software change. The Canary stage maps to your existing canary or progressive deployment: the canary metrics are the equivalent of canary error rates for a code deployment. The Active promotion maps to your existing production release: the promotion approval is the equivalent of a release sign-off.
The key difference is that rule changes typically move through these stages faster than software changes, because rules are evaluated in isolation (they do not have dependency trees, build processes, or integration test suites in the traditional sense). A rule change that follows the four-stage process from Draft to Active in 72 hours is normal. A software change that follows the same process in 72 hours would be unusually fast. This speed differential is an advantage: it means the process imposes minimal friction on teams that need to change rules frequently, which reduces the incentive to bypass it.
From Ad-Hoc to Governed: The Implementation Path
For teams currently operating without a rule change process, implementing the full four-stage model is not a single project. It is a progression. A practical implementation path:
Week 1-2: Rule inventory. Catalog every rule currently enforced in production. For each rule, record: what it does, where it is defined (prompt, config file, database, code), who owns it, and when it last changed. This inventory is the prerequisite for everything that follows. Most teams discover during this exercise that they have more rules than they thought, defined in more locations than they expected, with less documentation than they assumed.
Week 3-4: Draft stage implementation. Establish a standard format for rule definitions, a review checklist, and a test case template. Begin requiring that all new rule changes start as Draft entries with defined test cases and a reviewer. This can be implemented with nothing more than a shared document repository and a review process — no tooling is required at this stage.
Month 2-3: Shadow evaluation. Implement the infrastructure to evaluate shadow rules against live traffic and log their decisions without enforcement. This is the most technically demanding stage to build from scratch, as it requires a parallel evaluation path in your rule evaluation engine. Platforms that support shadow evaluation natively, such as Memrail's Safe Rollout, eliminate this infrastructure investment.
Month 3-4: Canary enforcement. Implement traffic-splitting for rule evaluation, allowing a configurable percentage of events to be routed to the new rule while the remainder continues under the current rule. Implement cohort metrics comparison to measure outcomes across the two cohorts.
Month 4-5: Rollback and automation. Implement instant rollback (single-operation reversion to the previous rule version) and automated rollback triggers (metric threshold breaches that trigger reversion without human intervention).
The result at the end of this progression is not a heavyweight governance bureaucracy. It is a lightweight, fast, well-instrumented process that makes rule changes safer, more transparent, and more frequent — because the cost of changing a rule safely is lower than the cost of changing it unsafely and dealing with the consequences. For a deeper look at how the safe rule rollout pattern applies specifically to SaaS decision rules, see the earlier article in this series.